Details on similarity measures¶
Discarding linear correlations¶
API name: discarding_linear_correlation
Options:
Reliability threshold (reliability_threshold)
Summary¶
Discarding linear correlation is the classical correlation, also called Pearson correlation, where samples that does not have a match with the same timestamp in the other series are discarded.
Description¶
Linear correlation is the most classical and widely adopted time series similarity measure. It is classically defined for equally sampled time series, but can be adapted to irregular sampling by discarding values that are not sampled for both series. Adaptations have been made with kernel based methods (Rehfeld, Marwan, Heitzig, & Kurths, 2011) to give a higher hit rate when samples are almost synchronized but not entirely, but it is actually equivalent to pre-aggregate the series with the proper smoother, and is thus useless in our case.
The main advantage of linear correlations is that they do not store samples because only one path is enough to compute first order (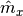 ) , second order (
) , second order ( 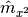 ), and cross series moment estimators (
), and cross series moment estimators ( 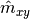 ).
).
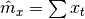
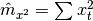
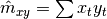
With these formulas, the computation of linear correlation is straightforward.
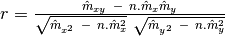
Where 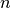 is the number of synchronized samples.
is the number of synchronized samples.
Parameter description¶
Reliability threshold: The reliability threshold specifies the minimum number of samples that need to be used in the correlation. If the requirement is not met the correlation score is set to 0 which allows you to easily discard this unreliable result.
DTW¶
API name: dtw
Options:
Reliability threshold (reliability_threshold)
Normalize (normalize)
Beta (beta)
Maximum delay (maximum_delay)
Local distance (local_distance)
Summary¶
DTW is the Dynamic Time Warping algorithm. Its specificity is that it compares pairs of samples, but allowing a fluctuation in a given time range (defined by the parameter called Maximum delay).
Description¶
Dynamic time warping is a distance measure between time signals that comes from the speech processing community but has been widely adopted by big data analysts. It is an adaptation of a classical distance measure that is tolerant to deviations in the time sampling. In speech processing its benefit is to adapt to sentences spoken at different speed. In general data analysis it is used because it tolerates divergences due to differences of data sources.
Going into the details of this technique is not in the scope of this report. A good introduction can be found in this paper: (Petitjean, Inglada, & Gançarski, 2012).
A few adaptations have been made to the technique to make it more coherent with our use case:
In particular a normalization pre-processing step has been added as an option to add the ability to detect pattern similarities even if series have different scales.
Another normalization is done according to the length of the warping. This normalization’s legitimacy can be discussed but it is a necessary evil when exploring data with different sampling rates.
The typical bands that are meant to limit computational complexity and memory consumption have been adapted to be based on the timestamps.
The local distance measure has be defined to be
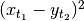 or
or 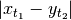 . The absolute value is usually used but the squared distance in conjunction with normalization corresponds to a generalization of the linear correlation which is an interesting property.
. The absolute value is usually used but the squared distance in conjunction with normalization corresponds to a generalization of the linear correlation which is an interesting property.DTW generates a distance
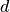 which is converted to a similarity measure using
which is converted to a similarity measure using 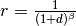 , where
, where 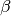 can be set to have any desired sensitivity. Indeed if is large only very small distances will be represented with a large similarity factor.
can be set to have any desired sensitivity. Indeed if is large only very small distances will be represented with a large similarity factor.
Parameter description¶
Reliability threshold: The reliability threshold specifies the minimum number of samples that need to be used in the correlation. If the requirement is not met the correlation score is set to 0 which allows you to easily discard this unreliable result.
Normalize: To make it scale free, the normalized option should be checked. It centers the series around their means and divides them by their variance before applying DTW
Beta: As DTW is originally a distance, it needs to be converted to a similarity measure. Beta allows to set the sensitivity of this sharpness. If it is close to 0 quite large distances will be represented as having non-negligible correlation. The larger it is the more severe the conversion is. It should not be smaller or equal to zero.
Maximum delay: The maximum delay is the temporal flexibility given to the warping.
Local distance: The local distance is the measure of distance between samples. It can be absolute or squared.
References¶
Martinez Heras, J., Yeung, K., Donati, A., Sousa, B., & Keil, N. (2009). DRMUST: Automating the Anomaly Investigation First-Cut. SpaceOps. Pasadena: American Institute of Aeronautics and Astronautics.
Petitjean, F., Inglada, J., & Gançarski, P. (2012). Satellite Image Time Series Analysis under Time Warping. IEEE Transactions on Geoscience and Remote Sensing.
Rehfeld, K., Marwan, N., Heitzig, J., & Kurths, J. (2011). Comparison of correlation analysis techniques for irregularly sampled time series. Nonlinear Processes.