Vertical aggregators¶
Overview¶
Vertical aggregators complete the capabilities of regular (horizontal) aggregators. They can be used on any query that has a group by tag. They aggregate the datapoints of the different series together.

Description¶
Available vertical aggregators:
Average
Min
Max
Difference
Preference
Sum
Note: The default vertical aggregator option selected in the UI is Average

Classical vertical aggregators: average, min, max, difference and sum¶
Classical aggregators have four boolean options.
Here is an example series grouped according to a given tag.
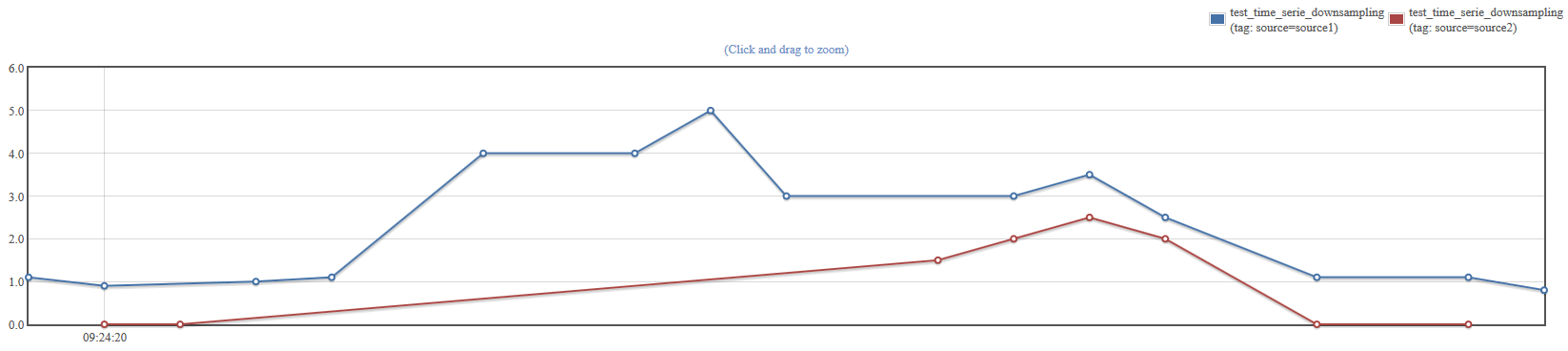
No options: performs the vertical aggregation each time a sample is met in one series, and only with the subset of series that actually have a sample with the same timestamp.
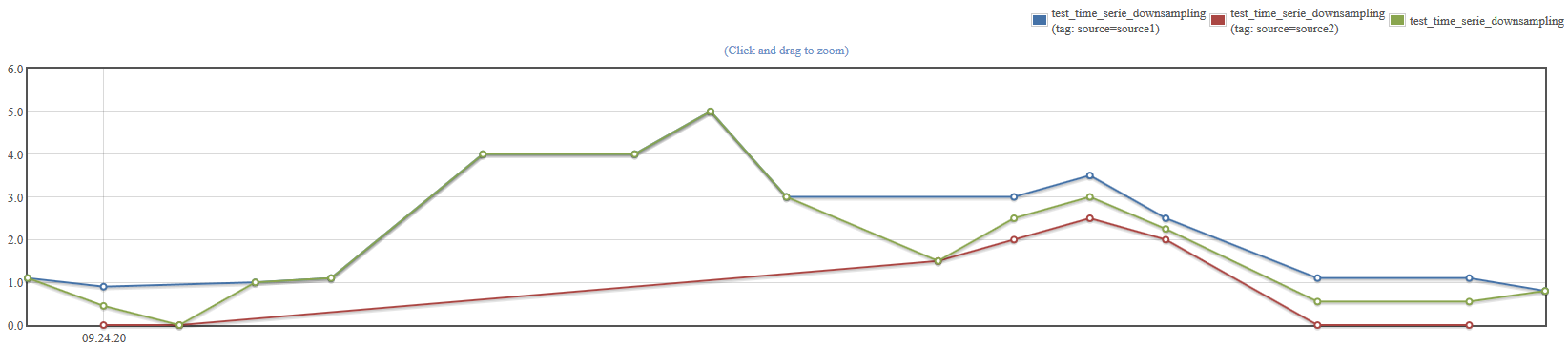
Start with last first: removes the points at the beginning of the time series until at least one measurement has been seen in every time series. This allows you to cut the series that start before the others.
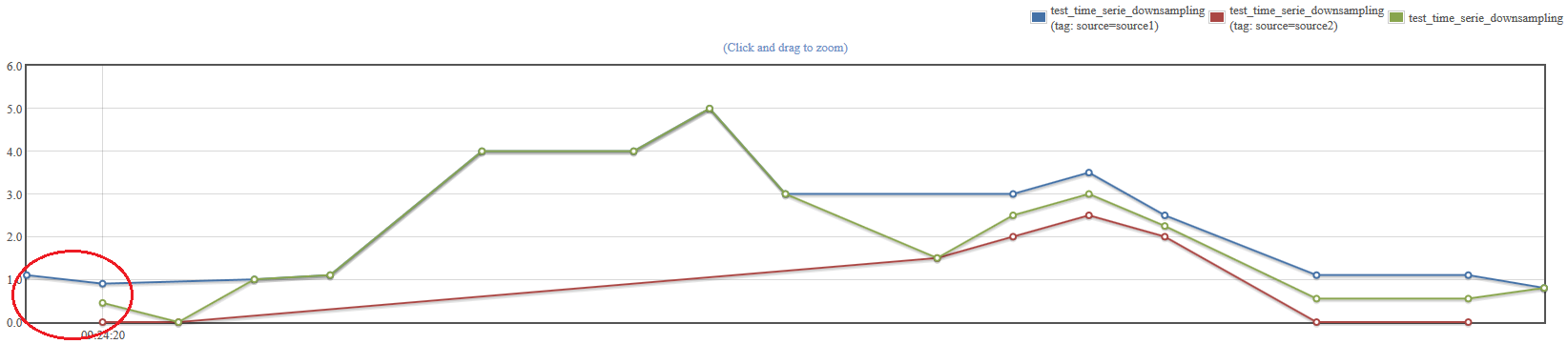
End with first last: same as the previous option but operates on the end of the sequence.
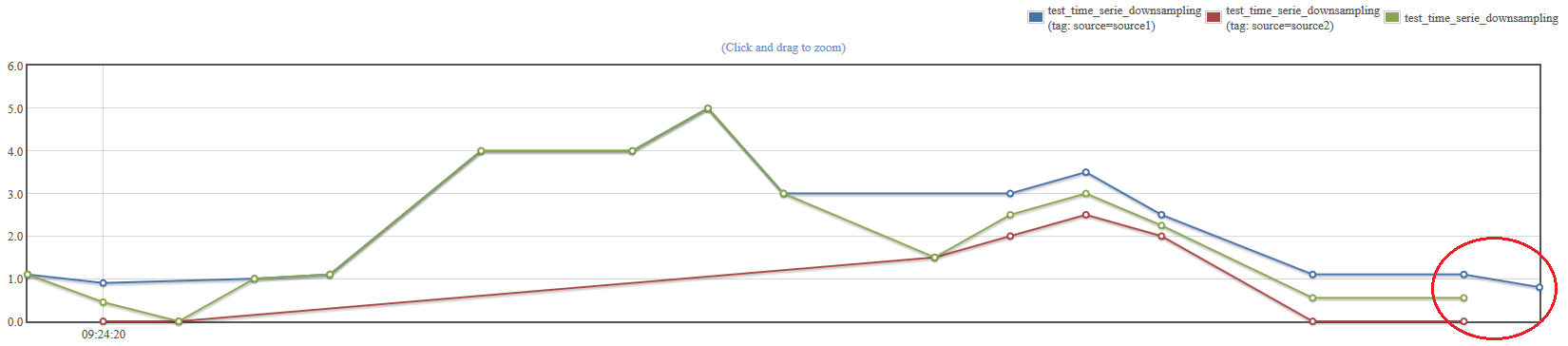
Interpolate with last: when a value is missing in one group it is replaced by the last value seen. If no value has been seen yet, aggregation is done between the other series. To have actual interpolation one must use the “interpolation” horizontal aggregator first.
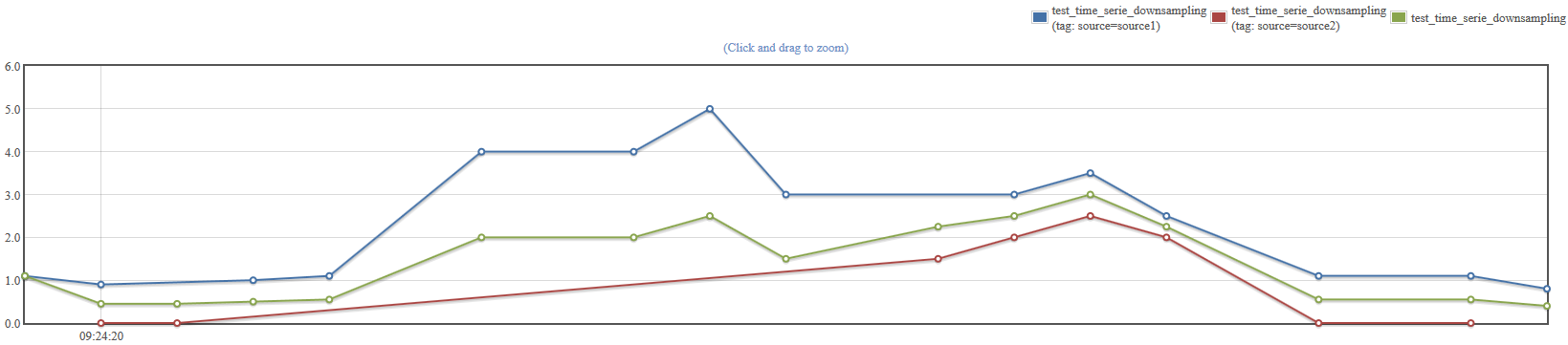
Discard unsynchronized: this automatically ignores the three previous parameters. Each time a value misses in one of the series, all the other points having the same timestamp are discarded.
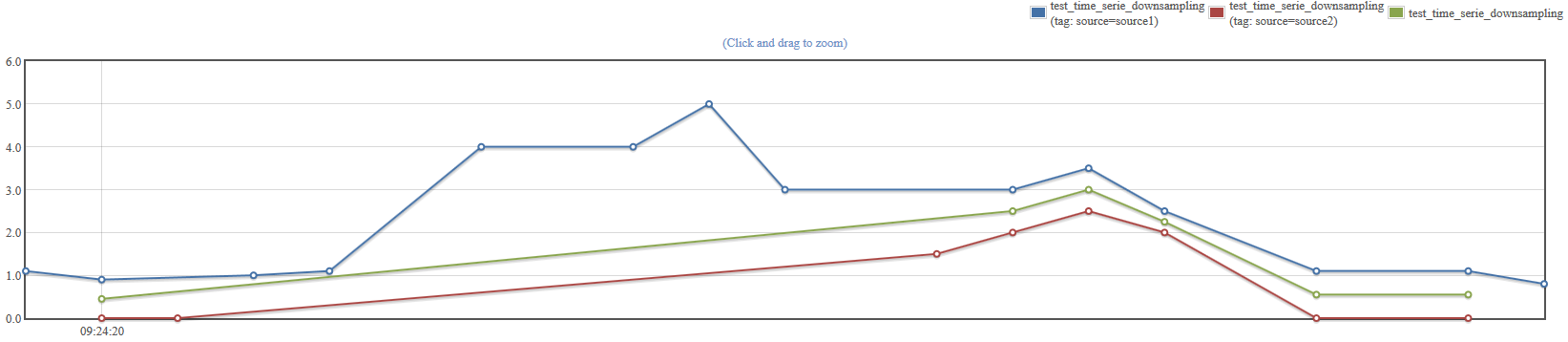
Note: difference aggregator is particular. It can only handle to series, and returns the absolute value of the difference.
Preference vertical aggregator¶
The preference aggregator works on two series. It allows the user to choose a series he prefers. If a sample is present in that series, it will be returned, otherwise the sample from the other series will be returned.
Interpolated vertical aggregator¶
To proceed to a vertical aggregation that uses interpolation to fill gap, use the interpolation horizontal aggregator which provides the linear interpolation of the series so it becomes regularly sampled. You can then chain it with any vertical aggregator presented in the previous sections.
Usage in API¶
The vertical aggregator is specified in an array in the vertical_aggregators attribute of the metric. There can be only one vertical aggregator object, and a name attribute is always specifying the nature of the aggregation.
Classical vertical aggregators¶
This is the list of classical vertical aggregators:
vertical_avg
vertical_sum
vertical_min
vertical_max
vertical_dif
These aggregators have four boolean parameters:
start_with_last_first
end_with_first_last
fill_with_last
discard_unsynchronized
Note that if discard_unsynchronized is set to true, the other 3 parameters are ignored. All parameters are false as default.
...
"vertical_aggregators": [
{
"name": "vertical_sum",
"fill_with_last": false
}
]
...
Error messages
Multiple samples with the same timestamp: vertical aggregators do not support series with more than one sample having the same timestamp
{
"errors": [
"The vertical aggregator cannot compute aggregation for data points with the same timestamp. You must precede it with another aggregator."
]
}
Difference aggregator only works with two series
{
"errors": [
"Difference aggregator only works with two series"
]
}
Preference vertical aggregator¶
Its name is vertical_pref. It has two parameter:
discriminating_tag
preferred_tag_value
Those represent the name and the value of the tag that should be preferred. Of course it requires that the data has been grouped according to a tag name that actually takes that value.
Error messages
An error message will be returned with status code 500 if:
the discriminating_tag parameter or the preferred_tag_value parameter is not specified
the tag value is not found in any of the groups aggregated
the discriminating tag has not been used as grouping tag
there are more than two groups
the preferred tag value is not found in any of the groups